Aschwanden's teaser subtitle: wisdom in the scientific crowd
Science writer Christine Aschwanden (@cragcrest) just published a nice summary of the October paper “Crowdsourcing Hypothesis Tests” by Landy et al.
Well, half the paper.
I like the WIRED piece. It covers the main result: if you give a dozen labs a novel hypothesis to tetst, they devise about a dozen viable ways to test it, with variable results. So what?
Anna Dreber, an economist at the Stockholm School of Economics and an author on the project. “We researchers need to be way more careful now in how we say, ‘I’ve tested the hypothesis.’ You need to say, ‘I’ve tested it in this very specific way.’ Whether it generalizes to other settings is up to more research to show.”
We often neglect this ladder of specificity from theory to experiment and the inevitable rigor-relevance tradeoff, so measuring the effect puts some humility back into our always too-narrow error bars.
But Anschwanden’s subtitle hints at more:
Just how much wisdom is there in the scientific crowd?
Perhaps some paragraphs were cut, because in the second part of the paper, Landy et al asked a crowd to forecast the outcomes of each variant. In his prize-winning Metascience poster Domenico Viganola (@dviganola) summarized the result:
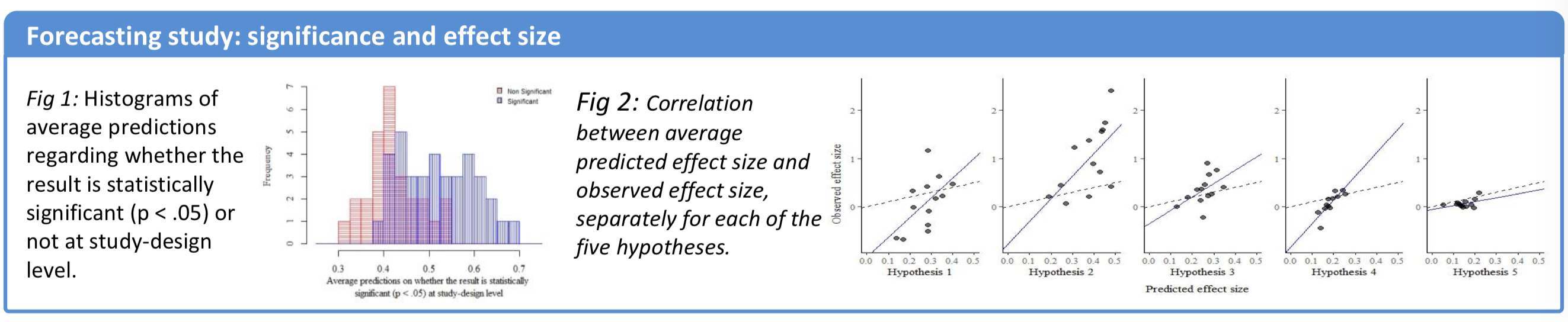
The scientific crowd was reasonably sensitive to the effect of the design variations from the different labs.
scientists’ predictions are positively correlated with the realized outcomes, both in terms of effect sizes and in terms of whether the result is statistically significant or not for the different sets of study materials.
And,
scientists were able to predict not only which hypotheses would receive empirical support (see Figure 3a) but also variability in results for the same hypothesis based on the design choices made by different research teams (see Figure 3b).
I think that’s pretty cool - and suggests there is reasonable wisdom in the scientific crowd.
But not quite enough wisdom to make this stud unnecessary.
Note: Dreber and Viganola are key part of the @ReplicationMkts team.
