I am slowly scanning old files and came across two page discussion of this medieval logic puzzle:
Socrates is whiter than Plato begins to be white.
I put the puzzle to Claude. Not bad.

I am slowly scanning old files and came across two page discussion of this medieval logic puzzle:
Socrates is whiter than Plato begins to be white.
I put the puzzle to Claude. Not bad.
Just heard my favorite self introduction:
“Remember the young scientist who ran into the room interrupting the 1994 NASA press conference about the comet colliding with Jupiter? That was me.” ~Heidi Hammel, approx.
A Joint Letter from 154 Bishops of The Episcopal Church - Whose Dignity Matters? From a month ago, but watching still gave me chills and hope and maybe courage.
Between this, the impossible numbers in the original laboratory study of cognitive dissonance, and a recent failure to replicate a basic dissonance effect, things aren’t looking great for [cognitive dissonance].¹ But that only makes me believe in it harder!
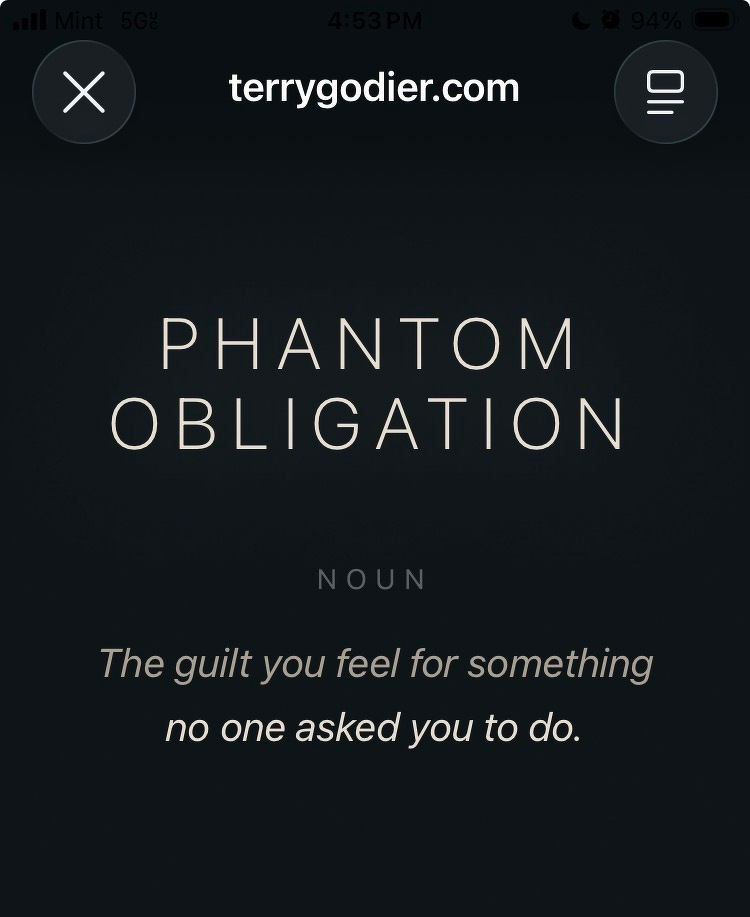
Concept by Terry Godier @tg that I didn’t know I needed. HTT @manton
Love for…
Part of a non-Tolkien thread on micro.blog; this post reminded me of the TeaWithTolkien community.
@calebgreene @teawithtolkien.bsky.social

| ❝ | That Western civilisation as we know it owes a very great deal to those, Augustine not least, who generated a vision of work, prayer and belief that overcame the decay and collapse of the Roman Empire. |

Andrew Sullivan today.

Paul Monk, writing about hope and peril for Venezuela in The Australian quotes Ellsberg:
There are situations, Ellsberg observed, …“in which the US government, starting ignorant, did not, would not learn. There was a whole set of what amounted to institutional ‘anti-learning’ mechanisms working to preserve and guarantee unadaptive and unsuccessful behaviour: the fast turnover in personnel; the lack of institutional memory at any level; the failure to study history; to analyse or even record operational experience or mistakes; the effective pressures for optimistically false reporting at every level, for describing ‘progress’ rather than problems or failures, thus concealing the need for change in approach or learning.”
| ❝ | The problem with all of us being so much more a hive mind than we realize is that knowledge problems that ripple across our a information ecosystems can become not just threats to individuals with weak character or bad habits, but the equivalent of colony collapse.† |
~Erin Kissane [Landslide: a ghost story](https://www.wrecka.ge/landslide-a-ghost-story/)

In the last year or two, listened to A.K. Larkwood’s fantasy trilogy: The Unspoken Name, The Thousand Eyes, and The Serpent Gates. I enjoyed the characters and the world, the soft magic based on old flawed gods, and the complex relationships. Excellent narration. 📚

Finally read (or listened to Andy Serkis read) The Silmarillion[ by J.r.r. Tolkien 📚. I can add little to all that has been written on it, but I recommend:

Early this year, read 2/3 of Seveneves by Neal Stephenson 📚. I found the struggle to secure a future in the face of imminent catastrophe excellent science fiction and human drama. I skipped the speculative evolution, though a friend suggested I revisit it as Stephenson’s take on Dune. Maybe.

Earlier this year, finished reading: The Infidel and the Professor by Dennis C. Rasmussen 📚as an audiobook. Recommended by a fellow History & Philosophy of Science graduate. I had read Hume ages ago but focused on causation and Newton. This was most welcome context. Excellent.

Finished: A Lady’s Life in the Rocky Mountains by Isabella Lucy Bird 📚 A friend recommended this exceptional 19th-Century travelogue of a British lady traveling alone in the Rocky Mountains back in the log-cabin days. A compilation of letters home, Bird is an excellent writer and keen observer.

Finished reading: Entheóphage by Drema Deòraich 📚
I bought it from the local (Virginia) author last year at Convivial. It’s now at 4.8 on Goodreads, with one review saying “Michael Crichton meets ecofiction in this scarily plausible medical thriller.” There is some Andromeda Strain but it didn’t quite land the plausible for me - though I loved the biology details along the way. Also, my thrill was muted by knowing up front the pandemic will spread. The protagonists Drs. Nadine Parker and Isobel Fallon are well-developed, and Kyn’s family is delightful, but their funders and bosses felt flat. The sudden ending artfully suggests how the open plots will resolve long-term, yet leaves the details to your imagination.
We put up with a great deal of environmental damage because it is far away. The book asks how that would change if our children literally felt it. The ending, I think, suggests it would take more.
A good first novel - I would definitely consider one of her later ones.
[edited]
…I was in academia at the time, where guaranteed suffering for uncertain gains is the name of the game. But I think a lot of us have Acceptable Suffering Ratios that are way out of whack. We believe ourselves to be in the myth of Sisyphus,…
Yglesias’ Slow Boring:
What’s gone up is not the cost of living relative to a single earner’s wages, but the opportunity cost of the second adult not working.
Interesting.
A reflection on Chesterton’s fence from Farnam Street.
The fence:
There exists in such a case a certain institution or law; let us say, for the sake of simplicity, a fence or gate erected across a road. The more modern type of reformer goes gaily up to it and says, “I don’t see the use of this; let us clear it away.” To which the more intelligent type of reformer will do well to answer: “If you don’t see the use of it, I certainly won’t let you clear it away. Go away and think. Then, when you can come back and tell me that you do see the use of it, I may allow you to destroy it.”
this comment by Colin Corbett seems a good explanation.

Huh. Didn’t expect that. HTT Ted Sanders.

I’ve been writing Python for 25 years. 🐍
So why do I still forget that .split() follows the string while .join() precedes it?
','.split('8,9') is not what I want.
Note: read this paper: stronger LLMs exhibit more cognitive bias. If robust, that would be a very promising result., as I noted in my comment to Kris Wheaton here.

So much Mountain Laurel!

On Weather Chimney Top, in WV.
A wonderfully hard (for me) and rewarding hike.

