Disclosure:

Disclosure:
Sabine Hossenfelder’s Do your own research… but do it right is an excellent guide to critical thinking and a helpful antidote to the meme that no one should “do your own research”.
To fix peer review, break it into stages, a short Nature opinion by Olava Amaral.
Essay worth reading in its entirety: The Great Reinforcer by Stuart Ritchie.
To be sure, out of the gloom of the pandemic came some incredible advances – the stunning progress made on vaccines chief among them. But these bright spots were something of an exception. For those of us with an interest in where science can go wrong, the pandemic has been the Great Reinforcer: it has underlined, in the brightest possible ink, all the problems we knew we had with the way we practice science.
Acknowledging stunning successes in the science of COVID-19, he reviews our regrettable and predictable failures. And hitting a little too close for comfort, notes how much harm comes from a desire to help.
Another great piece at Fantastic Anachronism: Are Experts Real.
I hadn’t heard about N=59. 😱
…if the N=59 crew are making such ridiculous errors in their own papers, they obviously don’t have the ability to judge other people’s…
In a recent Nature essay urging pre-registering replications, Brian Nosek and Tim Errington note:
Conducting a replication demands a theoretical commitment to the features that matter.
That draws on their paper What is a replication? and Nosek’s earlier UQ talk of the same name arguing that a replication is a test with “no prior reason to expect a different outcome.”
Importantly, it’s not about procedure. I wish I’d thought of that, because it’s obvious after it’s pointed out. Unless you are offering a case study, you should want your result to replicate when there are differences in procedure.
But psychology is a complex domain with weak theory. It’s hard to know what will matter. There is no prior expectation that the well-established Weber-Fechner law would fail among the Kalahri – but it would be interesting if it did. The well-established Müller-Lyer illusion does seem to fade in some cultures. That requires different explanations.
Back to the Nature essay:
What, then, constitutes a theoretical commitment? Here’s an idea from economists: a theoretical commitment is something you’re willing to bet on. If researchers are willing to bet on a replication with wide variation in experimental details, that indicates their confidence that a phenomenon is generalizable and robust. … If they cannot suggest any design that they would bet on, perhaps they don’t even believe that the original finding is replicable.
This has the added virtue of encouraging dialogue with the original authors rather than drive-by refutations. And by pre-registering, you both declare that before you saw the results, this seemed a reasonable test. Perhaps that will help you revise beliefs given the results, and suggest productive new tests.
The announcement of RR:C19 seems a critical step forward. Similar to Hopkins' Novel Coronavirus Research Compendium. Both are mentioned in Begley’s article.
So.. would it help to add prediction markets on replication, publication, citations?
PDF: US intervention timing simulations using county-level & mobility data: “had these same control measures been … 1-2 weeks earlier,” 55% of reported deaths could have been avoided. Strong claim. Haven’t looked, but counterfactuals are hard.
PDF: Simulation: age separation reduced C19 mortality even fixing interactions. “Separating just the older group… reduces the overall mortality… by 66%.” But “age separation is difficult.” ¿Is Erdös-Rényi an OK model here?
A non-random sample of new PDFs whose titles caught my eye yesterday. Based on a quick scan, so I may have missed something. (These are brand new PDFs - so use even more doubt than for well-published papers.)
Mortality rate and estimate of fraction of undiagnosed… cases… Simple amateur model estimates the mortality curve for US March & April diagnoses, using data from worldometers, and a Gaussian[!?] model. March peak death rate is on the 13th day after diagnosis, similar to Chinese data. Total mortality was 21%[!!?] suggesting severe under-testing [or data problems]. Whatever, the same method applied to cases after 1-APR finds 6.4%, suggesting more testing. If the real rate is 2.4% [!?], then 89% of March cases were untested and 63% of April cases. [The 2.4% IFR seems ~4x too high by other estimates. They got it by averaging rates from China, the Diamond Princess, Iceland, and Thailand. It’s not clear if they weighted those. First author cites themselves in a basically unrelated physics paper. But then, I’m not an epidemiologist either.]
[Estimation of the true infection fatality rate… in each country] (https://www.medrxiv.org/content/10.1101/2020.05.13.20101071v2?%253fcollection=) Short paper adjusting estimates because low PCR exam rate means exams are restricted to suspicious cases, and vice versa. “Reported IRs [infection rates] in USA using antibody tests were 1.5% in Santa Clara, 4.6% in Los Angeles county, and 13.9% in New York state, and our estimate of TIR [true infection rate] in the whole USA is 5.0%.” Estimates US IFR [infection fatality rate] as 0.6% [95% CI: 0.33 - 1.07], slightly higher than Germany and Japan’s ~0.5%, a bit lower than Sweden 0.7%, and much lower than Italy or the UK around 1.6%. [This is similar to the running Metaculus estimate, and note the 2.4% above is way outside the interval.]
Estimation of the infection fatality rate… More “simple methodology” but from claims to be from science & epi faculty in Mexico. They assume all members of a household will be infected together, which is plausible. But they don’t really dig into household data, and don’t really dig into case data, but just explore the method on “available data”. Eh.
Reproductive number of COVID-19: A systematic review and meta-analysis…: Global average of R=2.7 [95%CI 2.2-3.3] with lots of variation. They note that’s above WHO but lower than another summary. Among their 27 studies in their analysis, only two [both South Korea], publish estimates <1. Take with salt. By non-epidemiologists. They include Diamond Princess [R>14, albeit with large error bars]. And they claim method [MLE vs SEIR vs MCMC vs…] matters but they have so few samples per category and so many comparisons I don’t think it means anything.
Restarting after… Comparing policies and infections in the 16 states of Germany, the UC-Davis authors find that contact restrictions were more effective than border closures. Mobility data comes from Google. Using SEIR models, they then predict the effect of ways to relax policy. They think social distancing (German-style) reduced case counts by about 97% – equivalently, total case count would have been about 38X higher. Contact restrictions were estimated to be about 50% effective, versus about 2% for border closures. [What you’d expect for closing the gate after the Trojan horse is inside.] They put a lot of effort into modeling different parts of the transportation system: cars vs. trucks; public transit. They think that compared to keeping restrictions, lifting contact restrictions will cause a 51% or a 27% increase depending on scenarios. Relaxing initial business closures yields a 29% or 16% increase. Relaxing non-essential closures by 7% or 4%.
Relationship between Average Daily Temperature and… (v2). The authors say warmer is better, but note it could be UV or hidden correlation with eg age, pollution, social distancing, etc. And “when no significant differences exist in the average daily temperture of two cities in the same country, there is no significant difference in the average cumulative daily rate of confirmed cases.” Fifteen F-tests, and no obvious correction for multiple tests. I didn’t read in enough detail to know the right correction, but eyeballing the results, I’m guessing that would cut out half their “significant” correlations. Still, it remains plausible .
A surprising formula… A mathematician at UNC Chapel Hill claims surprising accuracy using a two-phase differential equations model. (Switches from one curve to the other at point of closest approach.) I haven’t had time to dive into the details, but I’m partial to phase-space for modeling dynamical systems. The paper argues for hard measures, once triggered, a theory the author calls epidemic “momentum managing”, which he expands in a longer linked piece.
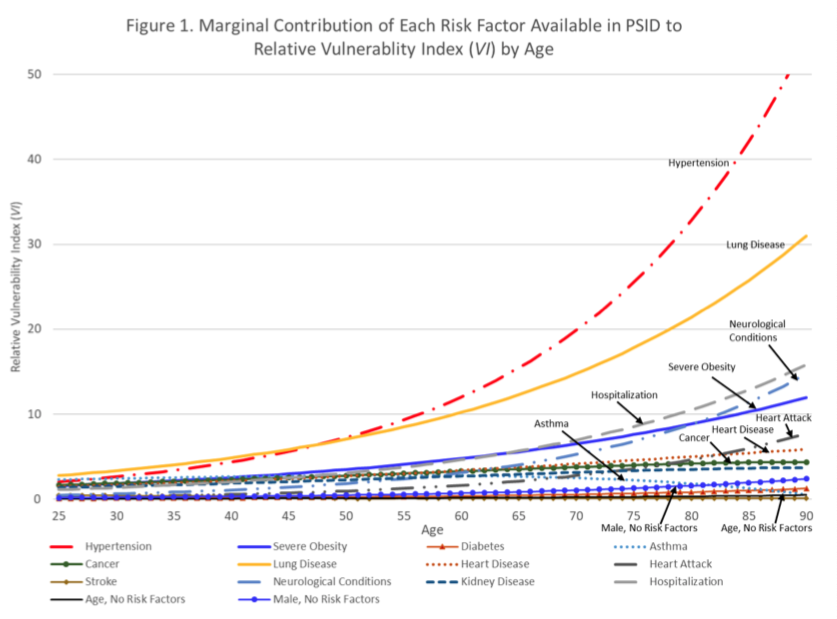
Disparities in Vulnerability… From 6 scholars in population health and aging, at 4 major US universities: “particular attention should be paid to the risk of adverse outcomes in midlife for non-Hispanic blacks, adults with a high school degree or less, and low-income Americans”. So, the usual. Oh, “our estimates likely understate those disparities.” An AI model trained on pre-pandemic medical claims created a vulnerability index for severe respiratory infection, by eduction, income, and race-ethnicity. High school education or less: 2x risk vs. college. Lowest income quartile: 3x risk vs highest. Both because of early onset underlying health conditions, esp. hypertension. See Risk Factor Chart below.
{kind=link}