Richard Hanania:
A remarkably high percentage of bad economic takes can be attributed to people being unable to realize the world is not zero-sum.
Richard Hanania:
A remarkably high percentage of bad economic takes can be attributed to people being unable to realize the world is not zero-sum.
In a discussion with @Somensi about excess deaths, I was puzzled by an apparent discrepancy between two sources that have both been reliable, insofar as I can tell:
The basic question from mid-December was how to reconcile this and this:
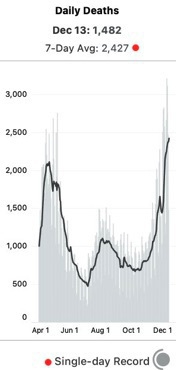 |
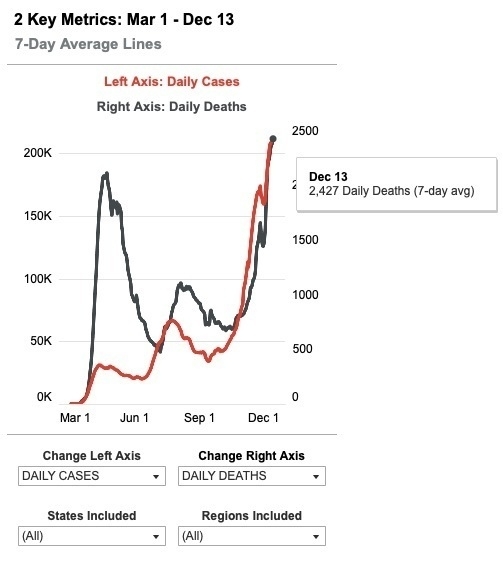 |
With this:
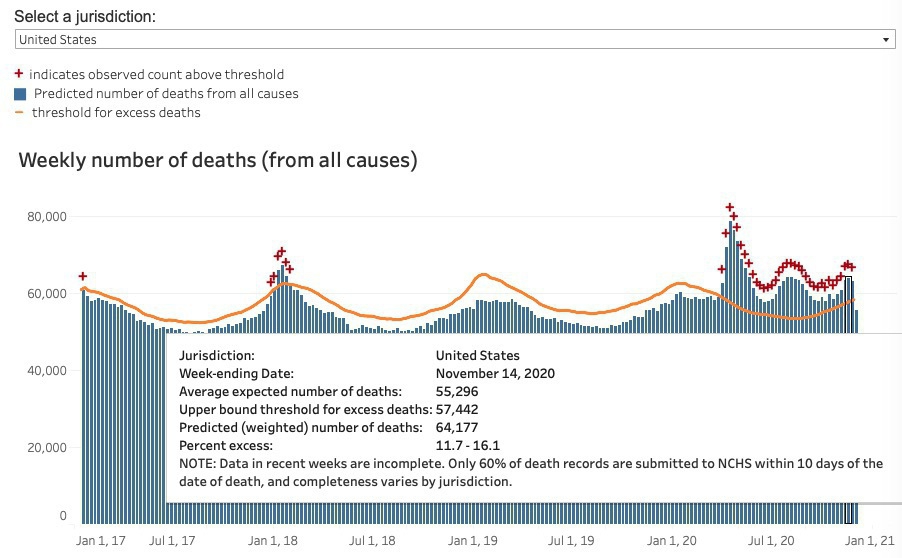
(Screenshots are from mid-Dec.)
In short, by early December it was clear that covidtracking.com had started diverging wildly from the CDC excess death counts. Two basic theories:
There’s a lot of noise on the thread, but @Somensi, who I don’t know, was also looking at data, and citing a good source. Doomsters like me have been using CDC excess data since April as evidence that the pandemic was real and could not be simple relabeling of flu deaths. Here the same source is cited to say the December spike couldn’t be real.
People on both sides who knew the CDC data understood it had a lag of 4 weeks or so – because it relies on actual death certificates completing all their procedural checks and getting filed. In 2016 it took 10 weeks for 80% of certificates to get filed. CDC now claims it gets to 60% in ~10 days. (There are plenty of people who don’t get the lag – it seems even to have tripped up JHU’s Dr. Briand, at least in her headline claim that there were no excess deaths in 2020.)
Problem: covidtracking is the most thoroughly-vetted weekly data source in the US. They’ve tracked the CDC excess deaths (after lag) the rest of the year. And reliably, their cases –predict–> hospitalizations 4 weeks later –predict–> deaths a few weeks later. The December death spike followed that pattern. Plausibly, CDC was just lagging.
Problem: CDC 4 weeks back should be pretty good, and it looked nothing like April. As my correspondent said, CDC data “would have to be lagging by an unprecedented amount."
It’s obvious once you see it.
That death spike (swoop?) at the end is super fast. If you hover over the attributed deaths chart from covid-tracking, you find that the Nov. 14 cases are exactly in line with their July numbers, about half their April numbers. And in line with the mid-Nov. CDC numbers. The steep rise is mostly in the last 4 weeks.

As of Dec. 23, we can look at how the CDC data has changed. Data should be pretty complete through Nov. 21. We see that Nov. 14 is now about 1,000 higher than before (and than the July peak), and Nov. 21 about 2,000 higher than that.
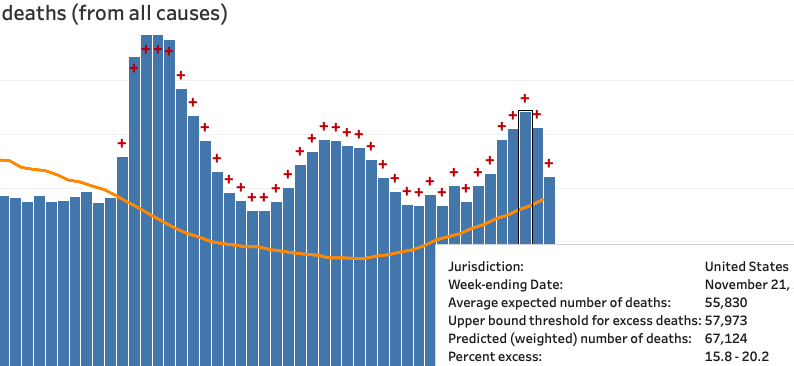
Not a swoop yet, but basically on par with the covidtracking chart week-for-week. Here that is again from today, highlighting Nov. 21. (The bold line is the 7-day moving average, a far better comparison than the daily total.)
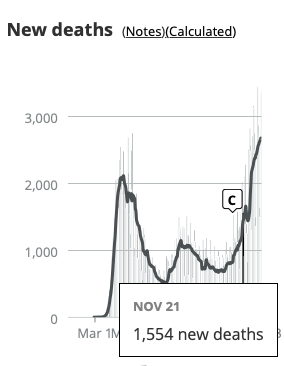
We should definitely expect the CDC excess deaths count for December to reach April levels.
Concentrate
An essay by Grand Master Jonathan Rowan, courtesy of Readup.
But, most of all, I miss the experience of concentration.
“next to of course god america i
love you land of the pilgrims’ and so forth oh
say can you see by the dawn’s early my
country ’tis of centuries come and go
and are no more. what of it we should worry
in every language even deafanddumb
thy sons acclaim your glorious name by gorry
by jingo by gee by gosh by gum
why talk of beauty what could be more beaut-
iful than these heroic happy dead
who rushed like lions to the roaring slaughter
they did not stop to think they died instead
then shall the voice of liberty be mute?”
He spoke. And drank rapidly a glass of water
e.e. cummings – Next to of course god america i | Genius
HTT Tipsy Teetotaler via @ReaderJohn for reminding me of this gem.
Sounds like a fun blog, just shouldn’t be masquerading as a journal.
Instead of saying, “I’m a woman and I reject gender roles,” NB ideology says, in effect, “I reject gender roles and therefore I’m not a woman.”
Not my area of expertise, but a fascinating reflection. If sex is only psychological, then “woman" contracts to the 1950s stereotype, and “lesbian” is defined out of existence. Backfire.
Excellent discussion between Sullivan and Yglesias.
Had to grit my teeth through some of Yglesias’ verbal ticks early to mid, but good points throughout. Perhaps esp arguing the counter productive nature of not acknowledging progress on women’s/gay/black rights, or later the dangers of a cult of woke (taking for granted the dangers of the cult of trump).
Our July paper Are replication rates the same across academic fields? Community forecasts from the DARPA SCORE programme was briefly cited at the end of a recent unpublished manuscript by Tosh et al, including Gelman. We’re source 13:
5.3 Implications for social science research
As noted at the beginning of this article, there has been a crisis in psychology, economics, and other areas of social science, with prominent findings and apparently strong effects that do not appear in attempted replications by outside research groups (e.g., [24, 2, 13]).
Always happy for the shout out, but our paper [13] doesn’t do replications. It just shows what our forecasters generally expected in upcoming replications, and that before looking at the actual study candidates. About 60 of those replications have happened, but have to wait for the Center for Open Science to announce them. In the meantime, Anna Dreber Almenberg has reached out to Gelman’s team.
The unpublished “Gelman” manuscript is:
The piranha problem: Large effects swimming in a small pond by C Tosh, P Greengard, B Goodrich, A Gelman, D Hsu. Abstract:
In some scientific fields, it is common to have certain variables of interest that are of particular importance and for which there are many studies indicating a relationship with a different explanatory variable. In such cases, particularly those where no relationships are known among explanatory variables, it is worth asking under what conditions it is possible for all such claimed effects to exist simultaneously. This paper addresses this question with formal theorems that show, unless the explanatory variables also have sizable effects on each other, it is impossible to have many such large effects.
Phil Tetlock (and no doubt others) have noted informally that something like this must hold.
I look forward to reading this piece on my new Remarkable tablet.
…is so desperate they solicit my “unpublished rhetoric” for the next issue.
I would like to Extol your elegant paper with Title …. It shows your potential and tenacity towards writing intrinsic paper.
Journal welcome Acumen like you to have your unpublished rhetoric and valuable paper on any related topic in …[long list of computer topics including “Debugs”]
Oh,
Glad to receive articles of atleast 1 or 2 pages on the topic of corona.
Because what we really need now is more computer scientists writing about the novel coronavirus.
The errors surpass Google Translate. Is this the Nigerian Prince scam but for academics, where the errors are deliberately left in place to select the audience?
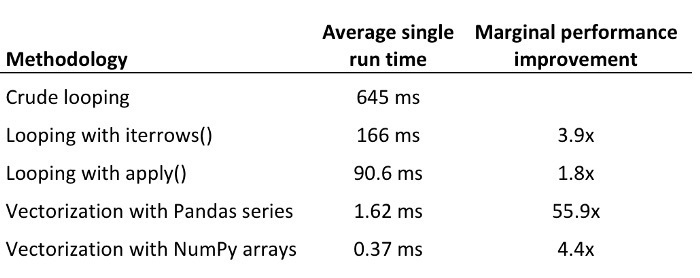
Optimizing Pandas
A clear and compelling example of vectorizing pandas code for 1700x speedup.

Recent climate thread by the always wonderful @KHayhoe, responding to the usual. Good videos too.
xkcd.com/808/ “Eventually, arguing that thesee things work means arguing that modern capitalism isn’t that ruthlessly profit-focused.”
Reductio… but not for health care. There’s plenty of obvious cost reduction they avoid because profits vary with costs. Misalignment.
I’m not sure “reblog” is a thin in µ.blog, but:
Recommendation for Breaking Bread with the Dead.
Ten Thousand xkcd.com/1053/
That said, watching the US President have dozens of these moments as he tried to come up to speed was not the kind of exciting I enjoy.

Sometimes in the evening, I return to do some work. But it’s late and hard to focus. I begin to #concentrate, and discover I have tried to read the internet.
🖊🗓#mbnov
Base Rates
www.smbc-comics.com/comic/ris…
HTT @rplzzz
🗓🖋#mbnov
‘’Once upon a planet dreary / Came a rocket engine cheery / On a flight to test a theory / On Mars’s frigid desert floor!
‘’Did life arise spontaneous / Or … / Seed the globe that now contains us? / Quoth the Lander, ‘Either-or.’ ‘’
~John A. Carroll 1977
This got my attention both because of its current echoes and because he’s right - I’ve forgotten it:
In this “moral panic” of thirty years ago, social workers and, later, prosecutors elicited from children horrific tales of Satan-worship, sexual abuse, and murder — and then, when anyone expressed skepticism, cried “We believe the children!” But every single one of the stories was false. … Moreover — and this is the point that I can’t stop thinking about — *the entire episode has been erased from our cultural memory. *
It pairs well with If Then, his reflection on reading the book of the same name.
When we, day by day and hour by hour, turn a direhose of distortion and misinformation directly into our own faces, we lose the ability to make measured judgments. We lash out against those we perceive to be our enemies and celebrate with an equally unreasonable passion those we deem to be our allies. … But there is another and still simpler problem with our presentism: we have no idea whether we have been through anything like what we are currently going through.
At this point he references his earlier post.
But only then does he begin to engage with If Then, where he points out that the current hope, hype, and fear of algorithms and technorati started 50 years ago with the Simulmatics corporation.
Which we’ve also forgotten.
l’ve seen some of the bizarre papers described in Maddie Blender’s article in Vice. Given their stream-of-consciousness technobabble, I thought they were generated by neural nets – I’ve gotten a couple of those during conference review, and read published papers describing automated paper-writers – but it appears there really is a bunch of circle-squarers who write and possible believe this stuff.
Most of it isn’t even fringe. It’s just BS - verbiage and ideas without regard for the idea of truth.
the bullshitter doesn’t care if what they say is true or false, but rather only cares whether their lister is persuaded.
As Pauli said, “not even wrong".
Dorothy Bishop, The Paper-in-a-Day Approach describes a once-a-year exercise her lab does to do a project in a mostly single intense session. Some key points:
When the Hubble Space Telescope allocation team launched dual-anonymous peer review for Hubble telescope time, the demographics of successful Principal Investigators (PIs) changed:
increasing the fraction of successful women PIs (such that the percentage of successful women PIs came within a point or two of successful male PIs), but also increasing the fraction of first-time PIs, suggesting that not only was there a historical gender bias but also a seniority bias.
Betteridge’s law of headlines:
“Any headline that ends in a question mark can be answered by the word no.”
Good summary by Jeremy Fox of Alvaro’s post, with a (closed) poll, & comments, including an excellent one by @repliCATS' Tim Parker.
Fox has written about replication before: here and elsewhere.
Suppose one reads a story of filthy atrocities in the paper. Then suppose that something turns up suggesting that the story might not be quite true, or not quite so bad as it was made out. Is one’s first feeling, ‘Thank God, even they aren’t quite so bad as that,’ or is it a feeling of disappointment, and even a determination to cling to the first story for the sheer pleasure of thinking your enemies are as bad as possible? If it is the second then it is, I am afraid, the first step in a process which, if followed to the end, will make us into devils. You see, one is beginning to wish that black was a little blacker. If we give that wish its head, later on we shall wish to see grey as black, and then to see white itself as black. Finally we shall insist on seeing everything – God and our friends and ourselves included – as bad, and not be able to stop doing it: we shall be fixed for ever in a universe of pure hatred.
Quote from Mere Christianity. Goodreads